CH16 트랜잭션과 락, 2차 캐시
isolation level
mysql isolation level 은 트랜젝션간의 순차성을 보장하기 위한 lock의 적용 여부를 선택적으로 조정하여 데이터 동시성을 제어하는 개념이다. 여기서 isolation은 흔히 트랜젝션의 속성으로 언급되는 ACID 를 이루는 I 로 트랜젝션 수행시 다른 트랜젝션이 끼어들어서 연산에 영향을 주지 못하게 하는(=고립을 시켜서) 것을 의미한다.
그래서 mysql isolation level를 이해하기 위해서는 먼저 isolation 상황을 조성해주는 lock에 대해서 학습을 해야한다.
동시성 이슈가 발생할 수 있는 원인은 애초에 특정한 트랜젝션이 어떤 데이터에 대해 특정한 처리를 한다고 할 때, 그 처리가 찰나로 이뤄지지 않고 아무리 짧더라도 결국 시각이 아닌 시간의 개념으로 일정 duration 이 소요되기 때문이다.
이 duration 동안 다른 트랜젝션이 끼어들어서 동일한 데이터에 다른 처리를 하게 되면 먼저 수행중인 트랜젝션이 의도와 다르게 처리할 가능성이 커진다. 이게 근본적으로 동시성 이슈가 발생하는 이유다.
이런 문제점을 방지하기 위해서는 직관적으로 보아도 첫번째 트랜젝션이 처리를 할 때 ‘다른 트랜젝션은 이거 보지도 말고 건들지도마’ 라고 하면 쉽게 해결 될 것으로 보인다. 혹은 ‘건들지마’까지만하고 보는 것은 허용해줘도 첫번째 트랜젝션의 처리에 영향을 주진 않을 것이다. 이런 제약의 개념이 바로 lock이며 mysql에서는 공유락(shared lock)과 베타락(exclusive lock) 이렇게 두 가지 종류의 lock이 존재한다.
개별 lock 에 대해서 알아보기 전에 mysql 공식문서에 나와있는 lock 의 정의를 보자.
The high-level notion of an object that controls access to a resource, such as a table, row, or internal data structure, as part of a locking strategy. For intensive performance tuning, you might delve into the actual structures that implement locks, such as mutexes and latches.
A kind of lock that allows other transactions to read the locked object, and to also acquire other shared locks on it, but not to write to it. The opposite of exclusive lock.
요약하자면 아래와 같다.
shared lock이 걸려있는 object 는 다른 트랜젝션이 read 는 가능하다.
shared lock이 걸려있는 object 는 다른 트랜젝션이 write 할 수 없다.
이미 shared lock이 걸려있는 object 에 따른 트랜젝션이 중첩해서 shared lock 을 걸 수 있다.
헷갈릴 수 있는 부분이 있는데(나는 헷갈렸다) 실습을 하다보면 shared lock이 걸려 있는데 다른 트랜젝션이 데이터를 바꿀 수 있었다. 문서에는 분명 shared lock이 걸려있으면 다른 트렌젝션의 write를 금지한다고 했는데? 왜 바뀌는걸까.
여기서 잘 알아둬야할 것이 write를 금지하는 대상은 shared lock 을 설정한 The object 인 것이다. 즉, shared lock을 설정할 때 select로 읽어들인 그 데이터에 대해서 불변을 보장(다른 트랜젝션의 write를 불허)한다는 것이다.
그래서 shared lock이 걸린 데이터라 해도 실제로 다른 트랜젝션이 update를 해서 디스크에 쓰는것 까지 모두 가능하다. 하지만 shared lock이 걸려있는 데이터는 디스크에서 바뀌었다고 해도 shared lock이 풀리기 전이라면 동일 트랜젝션 내에서 다시 select를 해도 여전히 변경 전의 데이터를 보게 된다.
나의 경우 이 차이에 대한 이해는 나중에 나올 mysql isolation level에서 READ COMMITED 와 REPEATABLE READ 의 차이를 이해할 때 중요하게 작용했다.
A kind of lock that prevents any other transaction from locking the same row. Depending on the transaction isolation level, this kind of lock might block other transactions from writing to the same row, or might also block other transactions from reading the same row. The default InnoDB isolation level, REPEATABLE READ, enables higher concurrency by allowing transactions to read rows that have exclusive locks, a technique known as consistent read.
요약하자면 아래와 같다.
exclusive lock 이 걸려있는 경우 같은 row에 대해서 다른 트랜젝션에 의한 중첩 lock은 금지시킨다.
exclusive lock 이 걸려있는 경우 같은 row에 대해서 다른 트랜젝션의 read, write 모두 금지 시킨다.
실제로 실험을 해보면 exclusive lock 을 걸어두고 다른 트랜젝션으로 같은 row에 대해서 update를 시도하면 하염없이 exclusive lock이 풀리기만을 기다리면서 시간이 흐른다.
동시성 제어가 되지 않으면 무슨 일이 발생할까? (신뢰할 수 없는 read에 대해 알아보기)
mysql isolation level를 이해하기 위해서 선행 학습해야할 개념이 lock 말고 하나가 더 있다. 동시성 제어가 되지 않았을 때 발생하는 ‘신뢰할 수 없는 read’를 유형별로 아는 것이다.
An operation that retrieves unreliable data, data that was updated by another transaction but not yet committed. It is only possible with the isolation level known as read uncommitted. This kind of operation does not adhere to the ACID principle of database design. It is considered very risky, because the data could be rolled back, or updated further before being committed; then, the transaction doing the dirty read would be using data that was never confirmed as accurate. Its opposite is consistent read, where InnoDB ensures that a transaction does not read information updated by another transaction, even if the other transaction commits in the meantime.
다른 트랜젝션에 의해서 아직 commit 되지 않은 데이터를 read 하는 경우이다.
다른 트랜젝션이 변경중이거나 추가한 데이터를 아직 커밋을 하지도 않았는데도 이를 읽어들이는 경우를 뜻한다. 이걸 롤백을 해버리면 무용지물이기 때문에 ‘정해지지 않은, 확정되지 않은’ 데이터라는 의미로 dirty 가 붙은 듯 하다.
단어 선택이 좀 확 와닿지 않아서 네이밍이 아쉽다는 생각이 들었다. 뭔가 ‘불완전의, 확정되지 않은’ 뭐 이런 느낌의 네이밍이 더 좋지 않았을까. 오로지 read uncommitted 레벨에서만 발생하는 오류 유형이다.
The situation when a query retrieves data, and a later query within the same transaction retrieves what should be the same data, but the queries return different results (changed by another transaction committing in the meantime). This kind of operation goes against the ACID principle of database design. Within a transaction, data should be consistent, with predictable and stable relationships. Among different isolation levels, non-repeatable reads are prevented by the serializable read and repeatable read levels, and allowed by the consistent read, and read uncommitted levels.
하나의 트랜젝션 내에서 동일한 쿼리를 두 번 실행했을 때, 나중에 실행한 쿼리가 첫번째 실행한 결과와 다른 결과를 가져오는 경우를 두고 non-repeatable read 라고 한다.
mysql isolation level 중 repeatable read 와 serializable read 는 동일 트랜젝션 내에서 shared lock 을 계속 걸어준 상태로 유지하기 때문에 non-repeatable read 현상이 나타나지 않는다. read committed 레벨에서는 나타날 수 있다.
A row that appears in the result set of a query, but not in the result set of an earlier query. For example, if a query is run twice within a transaction, and in the meantime, another transaction commits after inserting a new row or updating a row so that it matches the WHERE clause of the query. This occurrence is known as a phantom read. It is harder to guard against than a non-repeatable read, because locking all the rows from the first query result set does not prevent the changes that cause the phantom to appear. Among different isolation levels, phantom reads are prevented by the serializable read level, and allowed by the repeatable read, consistent read, and read uncommitted levels.
하나의 트랜젝션 내에서 동일한 쿼리를 두 번 실행했을 때, 나중에 실행한 쿼리에서 처음 실행한 쿼리에 없었던 row들이 생긴 경우이다. 반복 조회 시 결과 집합이 달라지는 것을 의미한다.
non-repeatable read 는 같은 row를 반복 조회했을때 결과가 다른 현상이고, phantom read 는 같은 쿼리로 반복 조회 했을때 결과 집합이 다른 현상이다.
트랜젝션 A의 첫번째 select 가 실행되고서 트랜젝션이 완료되기 전에 트랜젝션 B가 같은 테이블에 데이터를 insert-commit 한 경우, 트랜젝션 A가 첫번째 select 문을 다시 실행하면 아까 트랜젝션 B가 넣은 데이터가 추가되어 나오는 현상이다.
오직 serialize level 에서만 막을 수 있는 현상이다.
READ UNCOMMITTED
shared lock이 적용되지 않고, exclusive lock은 적용됨.
즉, consistent read를 보장하지 않는다. 그래서 모든 read 오류 유형이 나타날 수 있다.
READ COMMITTED(oracle 기본값)
shared lock, exclusive lock 모두 적용되지만 shared lock의 적용과 해제 시점이 좀 독특하다.
Each consistent read, even within the same transaction, sets and reads its own fresh snapshot.
공식문서를 보면 위와 같이 나와있는데 동일한 트랜젝션 내에서 매번 새로 lock을 걸고 해제하면서 각각의 fresh한 snapshot을 보여준다는 것이다. 그래서 READ COMMITTED의 경우에는 dirty read는 막을 수 있지만 non-repeatable read, phantom read는 막지 못한다.
REPEATABLE READ(mysql 기본값)
Consistent reads within the same transaction read the snapshot established by the first read.
동일한 트랜젝션 내에서 Consistent reads가 보장된다는 것이 핵심이다. 즉, 동일한 트랜젝션 내에서라면 처음 select 때 나온 스냅샷을 트랜젝션이 끝날때 까지는 반드시 보여준다는 의미이다.
두번째 select 시 나온 데이터가 첫번째 select와 다르면 undo log를 통해서 스냅샷을 유지하는 원리이다.
그래서 dirty read, non-repeatable read 모두를 막을 수 있지만 새로운 insert 는 막을 수 없으므로 phantom read는 발생한다.
SERIALIZABLE
phantom read까지 막아주는 isolation 강도가 가장 높은 level이다. 테이블 자체에 RANGE locks 을 걸어서 insert를 막는다고 한다.
트랜잭션과 락
‘낙관적 락’의 의미와 원리
충돌이 안날 것이라고 전제하는 락으로 커밋 전까지는 충돌여부를 알 수 없다. 커밋 시점이 되어서야 최초 조회시 읽은 version 과 비교해서 다르면 충돌을 일으킨다. 데이터베이스가 제공하는 락 기능을 사용하지 않고 어플리케이션에서 version 의 비교를 통해서 에러를 내는 방식인 것이다.
수정이 발생하면 @Version로 정한 컬럼의 값을 0부터 자동으로 증가시킨다.
수정이 발생하기 위해서는 조회시점의 version과 수정시점의 version이 일치해야하는데, 이것이 핵심이고 특별한 무엇인가가 있는게 아니라 update 문의 where 절에 version 에 대해서 조회시점의 version 으로 질의하는 조건을 추가한다.(아래 쿼리 참고)
이 version 값이 맞아야 update 가 되는 것이다. 맞지 않으면 조회되는 데이터가 없어서 에러가 발생한다.
LockModeType.OPTIMISTIC 옵션 기능
조회만 해도 트랜잭션이 끝나는 시점에 version을 다시 확인한다.
@Version 을 적용하면 update 문의 where 절에 version을 세팅하는 반면, LockModeType.OPTIMISTIC 을 적용하면 조회를 했을 때에도 트랜잭션 종료 시점에 version 의 일치여부를 다시 파악해보고 같지 않을 경우 예외를 발생시킨다.
@Version만 사용했을 때와 LockModeType.OPTIMISTIC 를 함께 사용했을때 동작이 다름을 정확하게 인지한다.
LockModeType.OPTIMISTIC_FORCE_INCREMENT 옵션 기능
조회만 해도 트랜잭션이 종료되는 시점에 version을 업데이트 한다. 논리적 단위로 엔티티의 변경을 판단하는 것이다.
예를 들어 포스팅 하나를 조회했을 때, 포스팅 자체 데이터는 아무것도 바뀌지 않았지만 포스팅을 읽은 사용자가 댓글을 하나 달았다던가, 좋아요를 눌렀다던가 하는 식으로 포스팅에 연관된 데이터를 변경한 경우 이는 ‘포스팅 데이터가 바뀌었다’라고도 표현할 수 있다.
이런 경우를 대비해서 보수적으로 판단해서 조회가 발생하면 해당 트랜잭션 중에 이미 뭔가가 변경이 발생했을 수 있겠다 라고 간주하고 version 을 올려버리는 것이다.
‘비관적 락’의 의미와 원리
비관적이라는 의미 그대로 충돌이 발생할 것이라고 전제하고 아예 row에 락을 걸어버리는 방법이다. 위에서 학습한 exclusive lock 을 row에 거는 것이다.
LockModeType.PESSIMISTIC_WRITE 옵션 기능
일반적으로 비관적 락이라고 할때 거는 옵션이다. mysql의 select for update 이 수행된다.
하나의 row 를 두고 두 트랜잭션이 동시에 접근하여 수정하고자 할 때, 수정 순서에 따라 하나의 수정 요청이 분실되는 문제이다.
이것의 해결책으로는 아래 세 가지가 있을 수 있다.
마지막 커밋만 인정하기
최초 커밋만 인정하기
충돌하는 갱신 내용 병합하기
낙관적 락을 사용하는 것이 최초 커밋을 인정하는 방법이다.
2차 캐시
2차 캐시 의미
1차 캐시는 영속성 컨텍스트 내로 스코프가 한정되었지만 2차 캐시는 어플리케이션 전체를 스코프로 가진다.
2차 캐시 작동원리 밎 중요사항
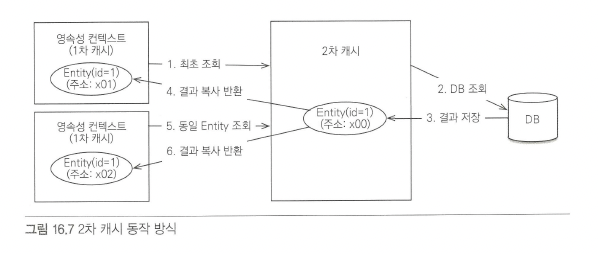
2차 캐시의 동작 방식은 아래와 같다.
영속성 컨텍스트는 엔티티가 필요하면 2차 캐시를 조회한다.
2차 캐시에 엔티티가 없으면 데이터베이스를 조회해서
결과를 2차 캐시에 보관한다.
2차 캐시는 자신이 보관하고 있는 엔티티를 복사해서 반환한다.
2차 캐시에 저장되어있는 엔티티를 조회하면 복사본을 만들어서 반환한다.
여기서 2차 캐시가 ‘복사본’을 반환한다는 것에 주목해야한다.
2차 캐시가 복사본을 반환하지 않고 가지고 있는 객체를 그대로 반환하는 경우 여러 곳에서 같은 객체를 동시에 수정하는 문제가 발생하게 된다. 동시에 수정하지 못하게 하려면 락을 걸어야하는데 동시성이 크게 떨어진다. 그래서 2차 캐시는 원본 대신에 복사본을 반환하는 것이다.
2차 캐시 뿐만이 아니라 전반적으로 챕터 16 전체를 정리해둔 포스팅이 있어서 링크를 남긴다. 그리고 2차 캐시에 관한 baeldung 포스팅 링크도 남긴다.
Last updated