도커 컨테이너 이해하기
1. 도커 컨테이너를 사용하는 이유
도커를 공부하면 제일 처음 접하게 되는 것이 ‘왜 도커를 쓰면 좋은지’ 이다. 그리고 도커의 장점을 설명하다가 나오는 개념이 바로 snow flake 이다. 쉽게 말해서 겉으로 보기엔 비슷한데 자세히 보면 각자가 다 다르다는 의미이다. 이를 서버에 적용해보면 각각의 서버가 여러 이유에 의해서 환경들이 제각각으로 세팅 되어서 일괄적으로 스케일업 하기도 힘들고, 이슈가 발생해도 이를 빠르게 일괄적으로 대응하기가 어렵다는 단점이 있다.
이를 해결하는 가장 좋은 방법은 완전히 동일한 서버 환경을 각각의 인스턴스에 갖추는 것이다. 물론 이렇게 하고자 의도하고 서버를 갖췄으니 그나마 겉으로는 다 같은 눈송이로 보이는 것이겠지만, 그럼에도 각 인스턴스의 환경(OS, 타 프로그램과의 충돌 등)에 의해 의도대로 ‘완전히 동일한 서버 환경’을 갖추는 것은 힘든 점이 많다.
이런 맥락에서 결국 해결책은 특정 환경에 종속되지 않은 상태로 어플리케이션을 구동하는 것이다. 특정 환경에 종속되지 않고, 기존의 가상화 방식이 야기하는 오버헤드를 피하도록 해주는 것이 바로 컨테이너 이다. 컨테이너는 아래와 같은 것들은 가능케 한다.(학습자료 발췌)
chroot 로 특정 자원만 사용하도록 제한
cgroup 을 사용하여 자원의 사용량을 제한
namespace로 특정 유저만 자원을 볼 수 있도록 제한
overlay network 등 네트워크 가상화 기술 활용
union file system (AUFS, overlay2)로 이식성, 비용절감
개인적으로 가장 뚜렷한 특장점은 다양한 OS환경에 구애받지 않고 배포가 가능하다는 이식성이 좋다는 것과 자원을 효율적으로 사용하도록 한다는 것이라 생각한다. 결국 궁극적인 목표는 immutable server를 만드는 것이다. (공부를 하다가 정리가 도커의 필요성에 대해 정리가 정말 잘 된 블로그 를 발견했다)
2. 도커 원리
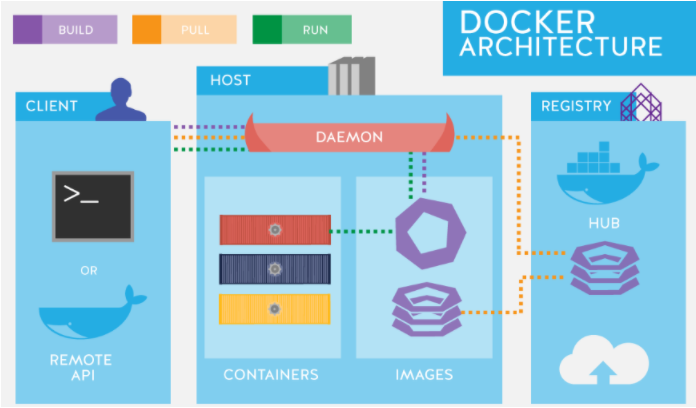
도커 데몬
강의에서는 VM의 관점에서 도커를 바라보지 말고 프로세스를 추상화 했다는 관점으로 바라보길 주문하고 있었다. 그게 이해가 더 쉬울거라는 이유에서. 아무튼, 도커 데몬 이 소켓을 열어두고 명령어를 받아서 파이프라인을 통해 해당 명령어를 보내서 적절한 작업을 수행한다. 컨테이너를 만든다던가 하는.
‘lsof -c docker’ 를 통해서 docker 명령어를 참조하고 있는 프로세스 리스트를 보면 아래와 같이 socket이 열려 있는 것을 확인할 수 있다.
컨테이너
2) 컨테이너는 이미지에 따라서 실행되는 환경(파일 시스템)이 달라진다. 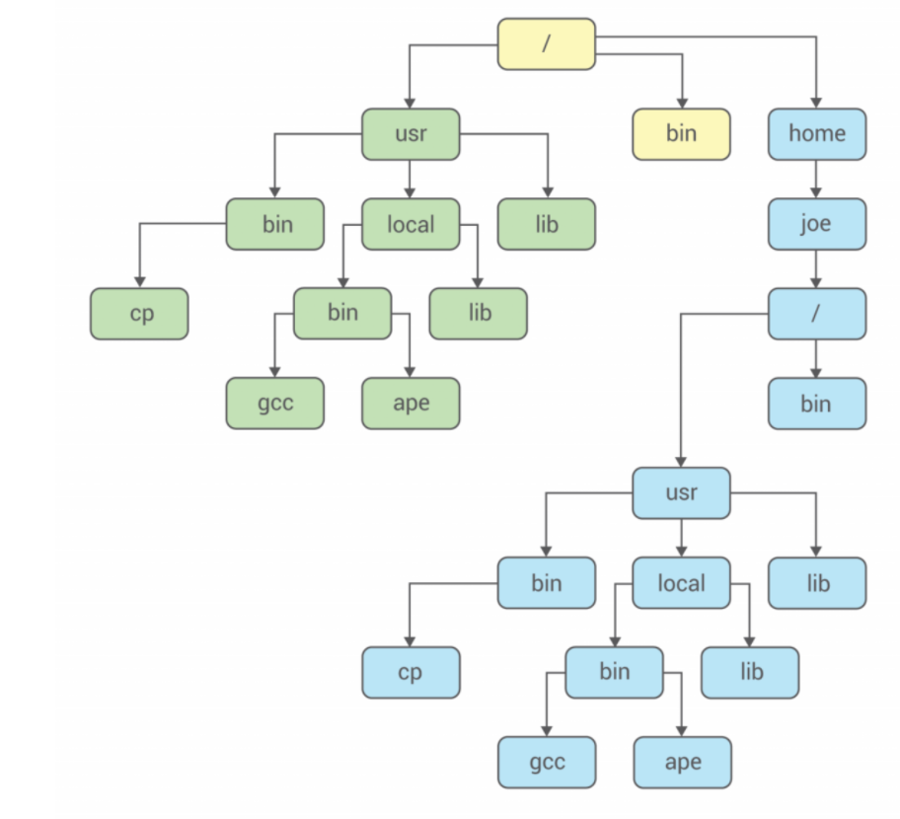
컨테이너 별로 각각 다른 파일 시스템을 가질 수 있는 이유는 chroot 를 활용하여 이미지(파일의 집합)를 루트 파일 시스템으로 강제로 인식시켜 프로세스를 실행하기 때문이다.
리눅스 종류, 버전 확인 : /etc/*-release
3) 컨테이너도 결국 프로세스
도커 네트워크 구조
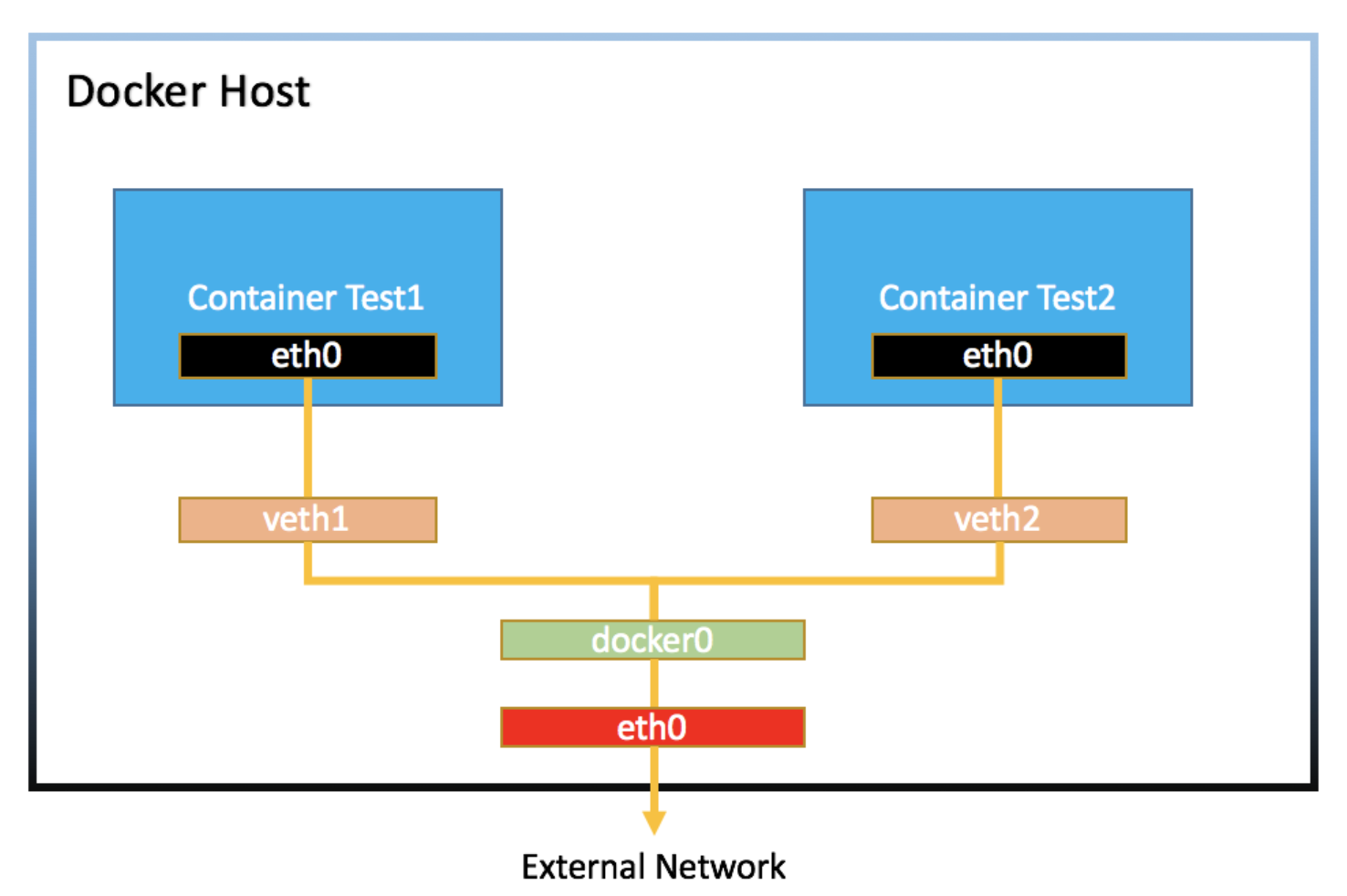
docker0는 스위치와 같은 역할을 한다
veth interface : 랜카드에 연결된 실제 네트워크 인터페이스가 아닌, 가상으로 생성한 네트워크 인터페이스. 일반적인 네트워크 인터페이스와는 달리 패킷을 전달받으면, 자신에게 연결된 다른 네트워크 인터페이스로 패킷을 보내주기 때문에 항상 쌍(pair)으로 생성해야 한다.
NET namespace : 리눅스 격리 기술인 namespace 중 네트워크와 관련된 부분을 말한다. 네트워크 인터페이스를 각각 다른 namespace에 할당함으로써 서로가 서로를 모르게끔 설정할 수 있다.
1) 생성되는 도커 컨테이너는 namespace 로 격리되고, 그 상태에서 통신을 위한 네트워크 인터페이스(eth0)를 할당받는다 2) host PC의 veth interface 가 생성되고 도커 컨테이너 내의 eth0 과 연결한다(컨테이너의 네트워크 격리를 달성하기 위해 선택한 방법인 것 같다) 3) host PC의 veth interface 는 docker0 이라는 다른 veth interface 와 연결된다 4) 이 과정이 컨테이너가 추가될 때 마다 반복된다
docker-compose 로 띄우면 다른 네트워크 대역을 가진다. docker-compose 로 컨테이너를 띄우면 compose 로 묶은 범위에 맞춰 브릿지를 하나 더 생성하기 때문이다. 따라서 서로 경유하는 브릿지가 다르므로 docker-compose로 띄운 컨테이너와 일반 컨테이너간의 통신은 불가능하다.
기본적으로 컨테이너는 외부와 통신이 불가능하다. 포트포워딩을 설정하여 외부에 컨테이너를 공개할 수 있다.
3. 도커 볼륨
예전에 도커 인프런 강의에서 이미 자세히 다뤘던 부분이라서 강의 자료만 그대로 옮긴다. 다음 번에 해당 이미지를 사용하면서 연동시켜 사용해야할 데이터가 있으면 이를 어떻게 보관하고 재사용 할 수 있을 것인가에 대한 해답이다.
도커 이미지로 컨테이너를 생성하면 이미지는 읽기 전용이 되며(immutable server가 된다는 뜻), 컨테이너의 변경 사항만 별도로 저장해서 각 컨테이너의 정보를 보존한다.
하지만 mysql과 같이 컨테이너 계층에 저장돼 있던 데이터베이스의 정보를 삭제해서는 안되는 경우도 있다. 이런 경우를 대비하여 컨테이너 데이터를 영속적인 데이터로 활용하기 위한 방법으로 볼륨을 활용하는 방안이 있다.
-v 옵션은 호스트의 디렉터리를 컨테이너의 디렉터리에 마운트한다. 따라서 컨테이너의 해당 경로에 파일이 있었다면 호스트의 볼륨으로 덮어씌워진다.
(이 두 문장이 포인트인 것 같다)
이처럼 컨테이너가 아닌 외부에 데이터를 저장하고 컨테이너는 그 데이터로 동작하도록 설계(stateless)하여야 한다. 컨테이너 자체는 상태가 없고 상태를 결정하는 데이터는 외부로부터 제공받도록 구성해야 한다.
Last updated